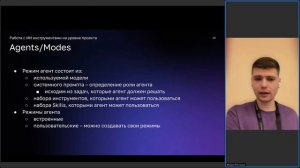
 1:01:34
1:01:34
2026-05-05 13:26
 19:60
19:60
19:60
2026-05-20 18:53
 14:47
14:47
14:47
2026-05-15 19:22
 9:23
9:23
9:23
2025-02-01 18:23
 7:46
7:46
7:46
2024-07-10 01:01
 5:44
5:44
5:44
2023-08-09 10:27
 0:32
0:32
0:32
2026-05-10 13:49
 5:29
5:29
5:29
2022-03-25 09:02
 3:16
3:16
3:16
2021-04-15 17:22
 7:11
7:11
7:11
2023-08-14 13:04
 21:55
21:55
21:55
2026-05-07 08:44
 9:41
9:41
9:41
2023-08-27 21:26
 5:32
5:32
5:32
2023-11-24 14:48
 6:25
6:25
6:25
2023-08-16 09:16
 8:39
8:39
8:39
2023-09-03 00:10
 9:08
9:08
9:08
2023-08-27 12:27
 13:31
13:31
13:31
2023-08-23 09:43
 43:04
43:04
![Sabi, MIA BOYKA - Базовый минимум (Премьера клипа 2026)]() 2:26
2:26
![Жасмин - Какое счастье (Премьера клипа 2026)]() 3:35
3:35
![StaFFорд63 - Наступит день (Премьера клипа 2026)]() 3:04
3:04
![Murat Gamidov - По ночам (Премьера клипа 2026)]() 2:53
2:53
![Руслан Шанов, Amina T - Не верну я (Премьера клипа 2026)]() 2:31
2:31
![Хуршида Намазбаева - Сени дея (Премьера клипа 2026)]() 4:17
4:17
![Xhensila – Gjuma (Official Video 2026)]() 2:18
2:18
![Инна Вальтер - Звёздный вечер (Премьера клипа 2026)]() 3:48
3:48
![Артур Халатов - Покайфуем (Премьера клипа 2026)]() 3:40
3:40
![Рустам Нахушев - Загубила (Премьера клипа 2026)]() 3:31
3:31
![Соня Белькевич, КРЕСТОВ - Станцуем (Премьера клипа 2026)]() 3:25
3:25
![Arujan - Koz tiydime (Премьера клипа 2026)]() 3:24
3:24
![Альберт Эркенов - По привычке (Премьера клипа 2026)]() 2:54
2:54
![Джатдай - Болит моя душа (Премьера клипа 2026)]() 2:14
2:14
![ARTIX, Анна Калайчева - Под гипнозом (Премьера клипа 2026)]() 2:29
2:29
![Zarina - Jojji Qaram (Official Video 2026)]() 3:15
3:15
![SHAXO, ILIMA - Чувства (Премьера клипа 2026)]() 2:34
2:34
![Ярослав Леонов - Майская роза (Премьера клипа 2026)]() 3:14
3:14
![Дана Лахова - Сердечко (Премьера клипа 2026)]() 3:15
3:15
![Ислам Итляшев - Мужское сердце (Премьера клипа 2026)]() 3:24
3:24
![Майк и Ник и Ник и Элис | Mike & Nick & Nick & Alice (2026)]() 1:47:10
1:47:10
![Аватар: Пламя и пепел | Avatar: Fire and Ash (2025)]() 3:17:14
3:17:14
![Микки 17 | Mickey 17 (2025)]() 2:16:60
2:16:60
![Последствия | Outcome (2026)]() 1:23:53
1:23:53
![Необычайно умные создания | Remarkably Bright Creatures (2026)]() 1:54:04
1:54:04
![На помощь! | Send Help (2026)]() 1:53:00
1:53:00
![Компаньон | Companion (2025)]() 1:37:08
1:37:08
![Эта штука работает? | Is This Thing On? (2026)]() 2:00:44
2:00:44
![В мгновение ока | In the Blink of an Eye (2026)]() 1:34:15
1:34:15
![Йети | The Yeti (2026)]() 1:33:08
1:33:08
![Мортал Комбат 2 | Mortal Kombat II (2026)]() 1:46:02
1:46:02
![Проект «Конец света» | Project Hail Mary (2026)]() 2:36:35
2:36:35
![Zомбилэнд: Контрольный выстрел | Zombieland: Double Tap (2019)]() 1:39:05
1:39:05
![Частная жизнь | Vie privée (2025)]() 1:47:21
1:47:21
![Крик 7 | Scream 7 (2026)]() 1:53:59
1:53:59
![Супер Марио: Галактическое кино | The Super Mario Galaxy Movie (2026)]() 1:38:05
1:38:05
![Супер Марио: Галактическое кино | The Super Mario Galaxy Movie (2026)]() 1:38:18
1:38:18
![GOAT: Мечтай по-крупному | GOAT (2026)]() 1:39:46
1:39:46
![Пицца фильм | Pizza Movie (2026)]() 1:37:12
1:37:12
![Завещание Анны Ли | The Testament of Ann Lee (2025)]() 2:16:48
2:16:48
![Новое ПРОСТОКВАШИНО]() 6:30
6:30
![Мартышкины]() 7:10
7:10
![Стражи Вселенной]() 1:04
1:04
![Пиратская школа]() 11:06
11:06
![Приключения Тайо]() 12:50
12:50
![Чемпионы]() 7:19
7:19
![Супер Зак]() 11:38
11:38
![Корги по имени Моко. Защитники планеты]() 4:33
4:33
![Сборники «Приключения Пети и Волка»]() 1:28:31
1:28:31
![Полли Покет Сезон 1]() 21:30
21:30
![Минифорс. Сила динозавров]() 12:51
12:51
![Тёплая анимация | Новая авторская анимация Союзмультфильма]() 20:49
20:49
![Сборники «Зебра в клеточку»]() 45:30
45:30
![Панда и петушок Лука]() 12:12
12:12
![Роботы-пожарные]() 12:31
12:31
![Последний книжный магазин]() 11:20
11:20
![МиниФорс]() 0:00
0:00
![Отряд А. Игрушки-спасатели]() 13:06
13:06
![Чуч-Мяуч]() 7:04
7:04
![Школьный автобус Гордон]() 12:34
12:34
![КЛИПЫ 90х ⭐Русский Сборник видеоклипов]() 2:54:39
2:54:39
![Дискотека 80-х 90-х Сборник видеоклипов (продолжение)]() 1:16:25
1:16:25
![ХИТЫ 2025 ТАНЦЕВАЛЬНАЯ МУЗЫКА СБОРНИК]() 1:41:18
1:41:18
![_*ДискотекА 80-90х ВиДео АлЬбом Лучшие.*_]() 2:40:60
2:40:60
![Пять ночей с Фредди 2 | Five Nights at Freddy's 2 (2025)]() 1:44:11
1:44:11
![Инна Вальтер - Дымом лечилась (Исповедь хулиганки)]() 7:04
7:04
![Барбоскины 1-30]() 2:21:36
2:21:36
![Смешарики (большой сборник)]() 3:25:27
3:25:27
![Bakhtin - Целовала (Премьера клипа 2023)]() 3:16
3:16
![Форсаж 9 | F9 (2021)]() 2:22:56
2:22:56
![Малыш. / 2026./ Россия / Боевик Драма Война]() 1:49:28
1:49:28
![Снова в деле (2025) Netflix]() 1:54:23
1:54:23
![Сборник На Кухне | Уральские Пельмени]() 1:30:27
1:30:27
![Дьявол носит Prada 2 | The Devil Wears Prada 2 (2026)]() 1:51:51
1:51:51
![Три Кота | Сборник домашних приключений | Мультфильмы для детей]() 45:14
45:14
![Барбоскины. Сезон 1. Серия 1. Пчёлка]() 5:38
5:38
![Алдан (2025)]() 1:38:04
1:38:04
![Давид | David (2025)]() 1:49:18
1:49:18
![Jakone и Kiliana - Асфальт (Mood Video)]() 2:50
2:50
![Сваты 1 сезон (сериал, 2008)]() 2:17:36
2:17:36
43:04

Скачать Видео с Рутуба по ссылке
| 256x144 | ||
| 424x240 | ||
| 640x360 | ||
| 848x480 | ||
| 1280x720 | ||
| 1920x1080 |
 2:26
2:26
2026-04-23 13:18
 3:35
3:35
2026-05-16 13:07
 3:04
3:04
2026-04-23 11:16
 2:53
2:53
2026-05-21 14:27
 2:31
2:31
2026-05-16 13:10
 4:17
4:17
2026-04-27 13:24
 2:18
2:18
2026-05-10 12:39
 3:48
3:48
2026-05-15 10:08
 3:40
3:40
2026-05-16 13:14
 3:31
3:31
2026-05-21 20:27
 3:25
3:25
2026-04-30 11:44
 3:24
3:24
2026-05-16 13:20
 2:54
2:54
2026-04-29 11:48
 2:14
2:14
2026-05-10 15:00
 2:29
2:29
2026-04-28 10:53
 3:15
3:15
2026-04-20 17:11
 2:34
2:34
2026-05-21 14:31
 3:14
3:14
2026-05-02 00:31
 3:15
3:15
2026-04-21 09:41
 3:24
3:24
2026-05-15 09:58
0/0
 1:47:10
1:47:10
2026-04-03 12:10
 3:17:14
3:17:14
2026-04-02 11:34
 2:16:60
2:16:60
2026-05-07 15:07
 1:23:53
1:23:53
2026-04-17 14:43
 1:54:04
1:54:04
2026-05-12 16:55
 1:53:00
1:53:00
2026-03-27 14:10
 1:37:08
1:37:08
2026-05-07 15:10
 2:00:44
2:00:44
2026-05-04 16:12
 1:34:15
1:34:15
2026-03-01 21:54
 1:33:08
1:33:08
2026-04-15 12:24
 1:46:02
1:46:02
2026-05-18 11:14
 2:36:35
2:36:35
2026-04-11 16:06
 1:39:05
1:39:05
2026-05-04 12:32
 1:47:21
1:47:21
2026-04-09 22:40
 1:53:59
1:53:59
2026-04-22 11:21
 1:38:05
1:38:05
2026-04-12 21:37
 1:38:18
1:38:18
2026-05-12 16:55
 1:39:46
1:39:46
2026-03-27 02:41
 1:37:12
1:37:12
2026-04-06 12:20
 2:16:48
2:16:48
2026-03-12 23:31
0/0
 6:30
6:30
2018-04-03 10:35
 7:10
7:10
2025-12-30 18:33
 1:04
1:04
2026-04-14 12:27
 11:06
11:06
2022-04-01 15:56
 12:50
12:50
2024-12-17 13:25
 7:19
7:19
2026-04-30 10:00
2021-09-22 22:07
 4:33
4:33
2024-12-17 16:56
 1:28:31
1:28:31
2026-03-05 13:25
2021-09-22 23:09
 12:51
12:51
2024-11-27 16:39
 20:49
20:49
2026-05-14 19:13
 45:30
45:30
2025-12-11 18:53
 12:12
12:12
2024-11-29 14:21
2021-09-23 00:12
 11:20
11:20
2025-09-12 10:05
 0:00
0:00
2026-05-22 08:55
 13:06
13:06
2024-11-28 16:30
 7:04
7:04
2022-03-29 15:20
 12:34
12:34
2024-12-02 14:42
0/0
 2:54:39
2:54:39
2022-03-11 11:17
 1:16:25
1:16:25
2022-09-19 10:59
2024-06-25 00:21
 2:40:60
2:40:60
2024-03-18 17:25
 1:44:11
1:44:11
2025-12-25 22:29
 7:04
7:04
2018-07-11 11:26
 2:21:36
2:21:36
2024-12-16 20:15
 3:25:27
3:25:27
2025-01-24 05:04
 3:16
3:16
2023-10-13 14:26
 2:22:56
2:22:56
2023-04-25 23:06
 1:49:28
1:49:28
2026-04-23 21:12
 1:54:23
1:54:23
2025-01-18 20:05
 1:30:27
1:30:27
2025-04-04 18:26
 1:51:51
1:51:51
2026-05-06 10:53
 45:14
45:14
2020-04-22 20:10
 5:38
5:38
2023-12-25 15:26
 1:38:04
1:38:04
2026-03-26 23:45
 1:49:18
1:49:18
2026-01-29 11:25
 2:50
2:50
2024-07-04 15:48
 2:17:36
2:17:36
2025-10-08 08:17
0/0