Спойлер лекции по автоматизированной обработке терминов из курса "Конвейер переводов: автоматизация работы переводчика"

Бартов: про работу с ИТ- и медтекстами и про всякое
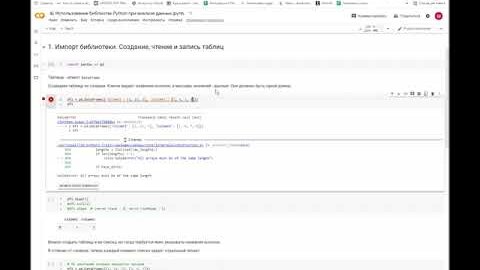
В этом видео я показываю процесс автоматизированного извлечения терминов и сборки двуязычных глоссариев с помощью Python-скриптов. Тут видна практическая механика: как из исходного текста получить структурированные данные, пригодные для дальнейшего использования в работе. Видео будет полезно не только переводчикам, но и редакторам, техническим писателям, копирайтерам — всем, кто ведет терминологическую работу или хочет унифицировать лексику в проектах и подключать готовые словари к ИИ-ассистентам и CAT-системам (Trados, SmartCat, MemoQ и другим). На экране — последовательная демонстрация настроек и результата обработки текста. На выходе зритель видит два готовых файла глоссария: один — в формате для CAT-программ, второй — оптимизированный для загрузки в ИИ-ассистента. Возможно будет вопрос: почему этот процесс нельзя сделать через ChatGPT или другие языковые модели? Потому что Python-скрипты дают другую скорость и глубину обработки на больших объемах текста (надо еще постараться впихнуть в модель 500 страниц текста). Кроме того, скрипты работают бесплатно, тогда как использование LLM (особенно на постоянной основе) предполагает оплату либо подписки, либо токенов. Здесь же — одноразовая настройка процесса и неограниченное использование.
 32:50
32:50