![[3Blue1Brown] Теория групп и 196883-мерный монстр](https://pic.rutubelist.ru/video/2024-11-20/a3/d3/a3d3c532bfcf35958d4d9a94ffcd0e9b.jpg?width=300) 21:49
21:49
2024-11-20 01:27
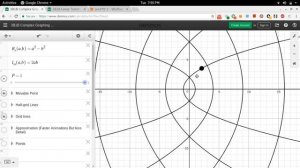 8:34
8:34
8:34
2023-12-02 13:03
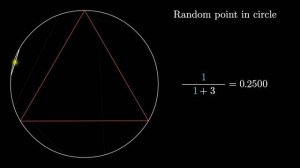 10:44
10:44
10:44
2023-12-02 16:12
![[3Blue1Brown] Сущность Линейной Алгебры. Введение](https://pic.rutubelist.ru/video/2024-11-20/7d/9f/7d9fd463822f226ac06552b574885509.jpg?width=300) 5:04
5:04
5:04
2024-11-20 01:01
 2:21:03
2:21:03
2:21:03
2024-09-29 21:40
 1:00:03
1:00:03
1:00:03
2024-10-01 16:05
 1:32:37
1:32:37
1:32:37
2024-11-28 13:51
 11:52
11:52
11:52
2025-07-26 20:00
 21:12
21:12
21:12
2025-08-03 20:36
 8:05
8:05
8:05
2025-08-03 20:24
 46:36
46:36
46:36
2024-09-27 18:09
 1:46:29
1:46:29
1:46:29
2023-10-21 17:44
 58:46
58:46
58:46
2024-09-27 18:00
 26:01
26:01
26:01
2024-09-26 19:17
 32:10
32:10
32:10
2024-09-30 11:00
 1:01:35
1:01:35
1:01:35
2024-09-25 19:21
 27:00
27:00
27:00
2024-10-01 01:30
 39:25
39:25
![Enrasta - За тобой (Премьера клипа 2025)]() 2:41
2:41
![Tural Everest, Руслан Добрый - Красивая (Премьера клипа 2025)]() 3:16
3:16
![Кравц - Пусть музыка играет (Премьера клипа 2025)]() 3:01
3:01
![Эльдар Агачев - Путник (Премьера клипа 2025)]() 3:14
3:14
![Бекзод Хаккиев - Нолалар (Премьера клипа 2025)]() 4:07
4:07
![Сирожиддин Шарипов - Хазонлар (Премьера клипа 2025)]() 3:09
3:09
![Абрикоса, GOSHU - Удали из памяти (Премьера клипа 2025)]() 4:59
4:59
![NYUSHA, ChinKong - Непогода (Премьера клипа 2025)]() 3:17
3:17
![МАРАТ & АРНИ - Я ЖЕНИЛСЯ (Премьера клипа 2025)]() 4:16
4:16
![Азамат Ражабов - Нигорим (Премьера клипа 2025)]() 3:52
3:52
![Маша Шейх - Будь человеком (Премьера клипа 2025)]() 2:41
2:41
![EDGAR - Мой брат (Премьера клипа 2025)]() 3:33
3:33
![ZAMA - Глаза цвета кофе (Премьера клипа 2025)]() 2:57
2:57
![Ахрор Гуломов - Ёмгирлар (Премьера клипа 2025)]() 3:49
3:49
![Даша Эпова - Мой любимый человек (Премьера клипа 2025)]() 2:11
2:11
![KAYA - Девочки, отмена (Премьера клипа 2025)]() 3:53
3:53
![Гайрат Усмонов - Унутаман (Премьера клипа 2025)]() 5:17
5:17
![Зара - Пилоты (Премьера клипа 2025)]() 3:51
3:51
![Рустам Нахушев - Письмо (Лезгинка) Премьера клипа 2025]() 3:27
3:27
![ARTEE - Ты моя (Премьера клипа 2025)]() 3:31
3:31
![Стив | Steve (2025)]() 1:33:34
1:33:34
![Однажды в Ирландии | The Guard (2011) (Гоблин)]() 1:32:16
1:32:16
![Хищник | Predator (1987) (Гоблин)]() 1:46:40
1:46:40
![Святые из Бундока | The Boondock Saints (1999) (Гоблин)]() 1:48:30
1:48:30
![Рок-н-рольщик | RocknRolla (2008) (Гоблин)]() 1:54:23
1:54:23
![Криминальное чтиво | Pulp Fiction (1994) (Гоблин)]() 2:32:48
2:32:48
![Все дьяволы здесь | All the Devils are Here (2025)]() 1:31:39
1:31:39
![Кровавый четверг | Thursday (1998) (Гоблин)]() 1:27:51
1:27:51
![Битва за битвой | One Battle After Another (2025)]() 2:41:45
2:41:45
![Плохой Санта 2 | Bad Santa 2 (2016) (Гоблин)]() 1:34:55
1:34:55
![Французский любовник | French Lover (2025)]() 2:02:20
2:02:20
![Школьный автобус | The Lost Bus (2025)]() 2:09:55
2:09:55
![Большое смелое красивое путешествие | A Big Bold Beautiful Journey (2025)]() 1:49:20
1:49:20
![Мужчина у меня в подвале | The Man in My Basement (2025)]() 1:54:48
1:54:48
![Заклятие 4: Последний обряд | The Conjuring: Last Rites (2025)]() 2:15:54
2:15:54
![Тот самый | Him (2025)]() 1:36:20
1:36:20
![Фантастическая четвёрка: Первые шаги | The Fantastic Four: First Steps (2025)]() 1:54:40
1:54:40
![Гедда | Hedda (2025)]() 1:48:23
1:48:23
![От заката до рассвета | From Dusk Till Dawn (1995) (Гоблин)]() 1:47:54
1:47:54
![Девушка из каюты №10 | The Woman in Cabin 10 (2025)]() 1:35:11
1:35:11
![Сборники «Простоквашино»]() 1:05:35
1:05:35
![Псэмми. Пять детей и волшебство Сезон 1]() 12:17
12:17
![Супер Дино]() 12:41
12:41
![Мотофайтеры]() 13:10
13:10
![Зебра в клеточку]() 6:30
6:30
![Оранжевая корова]() 6:30
6:30
![Пластилинки]() 25:31
25:31
![Мартышкины]() 7:09
7:09
![Сборники «Приключения Пети и Волка»]() 1:50:38
1:50:38
![Простоквашино. Финансовая грамотность]() 3:27
3:27
![Поймай Тинипин! Королевство эмоций]() 12:24
12:24
![Люк - путешественник во времени]() 1:19:50
1:19:50
![Приключения Тайо]() 12:50
12:50
![Синдбад и семь галактик Сезон 1]() 10:23
10:23
![МиниФорс]() 0:00
0:00
![Артур и дети круглого стола]() 11:22
11:22
![Пингвиненок Пороро]() 7:42
7:42
![Минифорс. Сила динозавров]() 12:51
12:51
![Роботы-пожарные]() 12:31
12:31
![Супер Зак]() 11:38
11:38
39:25

Скачать Видео с Рутуба / RuTube
| 256x144 | ||
| 424x240 | ||
| 640x360 | ||
| 848x480 | ||
| 1280x720 |
 2:41
2:41
2025-11-07 14:04
 3:16
3:16
2025-11-12 12:12
 3:01
3:01
2025-11-07 14:41
 3:14
3:14
2025-11-12 12:52
 4:07
4:07
2025-11-11 17:31
 3:09
3:09
2025-11-09 16:47
 4:59
4:59
2025-11-15 12:21
 3:17
3:17
2025-11-07 13:37
 4:16
4:16
2025-11-06 13:11
 3:52
3:52
2025-11-07 14:08
 2:41
2:41
2025-11-12 12:48
 3:33
3:33
2025-11-07 13:31
 2:57
2:57
2025-11-13 11:03
 3:49
3:49
2025-11-15 12:54
 2:11
2:11
2025-11-15 12:28
 3:53
3:53
2025-11-06 12:59
 5:17
5:17
2025-11-06 13:07
 3:51
3:51
2025-11-11 12:22
 3:27
3:27
2025-11-12 14:36
 3:31
3:31
2025-11-14 19:59
0/0
 1:33:34
1:33:34
2025-10-08 12:27
 1:32:16
1:32:16
2025-09-23 22:53
 1:46:40
1:46:40
2025-10-07 09:27
 1:48:30
1:48:30
2025-09-23 22:53
 1:54:23
1:54:23
2025-09-23 22:53
 2:32:48
2:32:48
2025-09-23 22:52
 1:31:39
1:31:39
2025-10-02 20:46
 1:27:51
1:27:51
2025-09-23 22:52
 2:41:45
2:41:45
2025-11-14 13:17
 1:34:55
1:34:55
2025-09-23 22:53
 2:02:20
2:02:20
2025-10-01 12:06
 2:09:55
2:09:55
2025-10-05 00:32
 1:49:20
1:49:20
2025-10-21 22:50
 1:54:48
1:54:48
2025-10-01 15:17
 2:15:54
2:15:54
2025-10-13 19:02
 1:36:20
1:36:20
2025-10-09 20:02
 1:54:40
1:54:40
2025-09-24 11:35
 1:48:23
1:48:23
2025-11-05 19:47
 1:47:54
1:47:54
2025-09-23 22:53
 1:35:11
1:35:11
2025-10-13 12:06
0/0
 1:05:35
1:05:35
2025-10-31 17:03
2021-09-22 22:23
 12:41
12:41
2024-11-28 12:54
 13:10
13:10
2024-11-27 14:57
 6:30
6:30
2022-03-31 13:09
 6:30
6:30
2022-03-31 18:49
 25:31
25:31
2022-04-01 14:30
 7:09
7:09
2025-04-01 16:06
 1:50:38
1:50:38
2025-10-29 16:37
 3:27
3:27
2024-12-07 11:00
 12:24
12:24
2024-11-27 13:24
 1:19:50
1:19:50
2024-12-17 16:00
 12:50
12:50
2024-12-17 13:25
2021-09-22 23:09
 0:00
0:00
2025-11-15 20:14
 11:22
11:22
2023-05-11 14:51
 7:42
7:42
2024-12-17 12:21
 12:51
12:51
2024-11-27 16:39
2021-09-23 00:12
2021-09-22 22:07
0/0