 5:48
5:48
2025-11-04 21:45
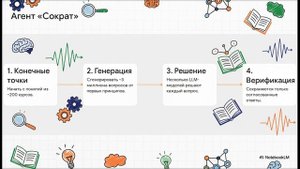 7:20
7:20
7:20
2025-11-04 19:05
 7:35
7:35
7:35
2025-11-04 15:55
 58:46
58:46
58:46
2024-09-27 18:00
 54:23
54:23
54:23
2024-09-28 15:18
 26:01
26:01
26:01
2024-09-26 19:17
 1:53:18
1:53:18
1:53:18
2024-09-28 21:00
 30:22
30:22
30:22
2024-09-29 12:00
 32:10
32:10
32:10
2024-09-30 11:00
 29:05
29:05
29:05
2024-09-26 12:57
 1:09:36
1:09:36
1:09:36
2024-09-25 17:56
 1:11:49
1:11:49
1:11:49
2024-10-02 21:00
 27:00
27:00
27:00
2024-10-01 01:30
 46:36
46:36
46:36
2024-09-27 18:09
 39:25
39:25
39:25
2024-09-27 15:00
 32:07
32:07
32:07
2024-09-30 15:00
![ДАР УБЕЖДЕНИЯ | НАДЕЖДА СЫСОЕВА]() 49:20
49:20
 49:20
49:20
2024-10-02 17:03
 1:05:04
1:05:04
![Нодир Иброҳимов - Жоним мени (Премьера клипа 2025)]() 4:01
4:01
![Алмас Багратиони - Сила веры (Премьера клипа 2025)]() 3:18
3:18
![Бобур Ахмад - Куролмаслар (Премьера клипа 2025)]() 3:33
3:33
![Илёс Юнусий - Каранг она якинларим (Премьера клипа 2025)]() 3:36
3:36
![BITTUEV - Не плачь (Премьера клипа 2025)]() 2:18
2:18
![Джатдай - Забери печаль (Премьера клипа 2025)]() 2:29
2:29
![Сергей Одинцов - Девочка любимая (Премьера клипа 2025)]() 3:56
3:56
![Bruno Mars ft. Ed Sheeran – Home to You (Official Video 2025)]() 3:25
3:25
![Сардор Расулов - Етолмадим (Премьера клипа 2025)]() 4:15
4:15
![Зара - Прерванный полет (Премьера клипа 2025)]() 5:08
5:08
![ARTIX - Ай, джана-джана (Премьера клипа 2025)]() 2:24
2:24
![Инна Вальтер - Роза (Премьера клипа 2025)]() 3:18
3:18
![Рустам Нахушев, Зульфия Чотчаева - Каюсь (Премьера клипа 2025)]() 3:20
3:20
![Зафар Эргашов & Фируз Рузметов - Лабларидан (Премьера клипа 2025)]() 4:13
4:13
![SHAXO - Негодяйка (Премьера клипа 2025)]() 3:27
3:27
![SERYABKINA, Брутто - Светофоры (Премьера клипа 2025)]() 3:49
3:49
![Слава - В сердце бьёт молния (Премьера клипа 2025)]() 3:30
3:30
![Наталья Влади - Я обещаю (Премьера клипа 2025)]() 3:00
3:00
![Мухит Бобоев - Маликам (Премьера клипа 2025)]() 3:18
3:18
![Иброхим Уткиров - Коракуз (Премьера клипа 2025)]() 4:28
4:28
![Псы войны | Hounds of War (2024)]() 1:34:38
1:34:38
![Эффект бабочки | The Butterfly Effect (2003)]() 1:53:35
1:53:35
![Храброе сердце | Braveheart (1995)]() 2:57:46
2:57:46
![Свинья | Pig (2021)]() 1:31:23
1:31:23
![Сумерки | Twilight (2008)]() 2:01:55
2:01:55
![Хани, не надо! | Honey Don't! (2025)]() 1:29:32
1:29:32
![Стив | Steve (2025)]() 1:33:34
1:33:34
![Хищник | Predator (1987) (Гоблин)]() 1:46:40
1:46:40
![Богомол | Samagwi (2025)]() 1:53:29
1:53:29
![Диспетчер | Relay (2025)]() 1:51:56
1:51:56
![Пойман с поличным | Caught Stealing (2025)]() 1:46:45
1:46:45
![Только ты | All of You (2025)]() 1:38:22
1:38:22
![F1 (2025)]() 2:35:53
2:35:53
![Кей-поп-охотницы на демонов | KPop Demon Hunters (2025)]() 1:39:41
1:39:41
![Лучшее Рождество! | Nativity! (2009)]() 1:46:00
1:46:00
![Девушка из каюты №10 | The Woman in Cabin 10 (2025)]() 1:35:11
1:35:11
![Тот самый | Him (2025)]() 1:36:20
1:36:20
![Мужчина у меня в подвале | The Man in My Basement (2025)]() 1:54:48
1:54:48
![Обитель | The Home (2025)]() 1:34:43
1:34:43
![Школьный автобус | The Lost Bus (2025)]() 2:09:55
2:09:55
![Панда и петушок Лука]() 12:12
12:12
![Забавные медвежата]() 13:00
13:00
![Сборники «Приключения Пети и Волка»]() 1:50:38
1:50:38
![Корги по имени Моко. Новый питомец]() 3:28
3:28
![Сборники «Оранжевая корова»]() 1:05:15
1:05:15
![Школьный автобус Гордон]() 12:34
12:34
![Паровозик Титипо]() 13:42
13:42
![Простоквашино. Финансовая грамотность]() 3:27
3:27
![Умка]() 7:11
7:11
![Команда Дино Сезон 2]() 12:31
12:31
![Кадеты Баданаму Сезон 1]() 11:50
11:50
![Роботы-пожарные]() 12:31
12:31
![МегаМен: Полный заряд Сезон 1]() 10:42
10:42
![Зебра в клеточку]() 6:30
6:30
![Лудлвилль]() 7:09
7:09
![Ну, погоди! Каникулы]() 7:09
7:09
![Панда и Антилопа]() 12:08
12:08
![Пластилинки]() 25:31
25:31
![Истории Баданаму Сезон 1]() 10:02
10:02
![Чемпионы]() 7:35
7:35
1:05:04

Скачать видео
| 256x144 | ||
| 424x240 | ||
| 640x360 | ||
| 848x480 | ||
| 1280x720 |
 4:01
4:01
2025-11-02 10:14
 3:18
3:18
2025-10-24 12:09
 3:33
3:33
2025-11-02 10:17
 3:36
3:36
2025-11-02 10:25
 2:18
2:18
2025-10-31 15:53
 2:29
2:29
2025-10-24 11:25
 3:56
3:56
2025-10-28 11:02
 3:25
3:25
2025-11-02 10:34
 4:15
4:15
2025-10-26 12:52
 5:08
5:08
2025-10-31 12:50
 2:24
2:24
2025-10-28 12:09
 3:18
3:18
2025-10-28 10:36
 3:20
3:20
2025-10-30 10:39
 4:13
4:13
2025-10-29 10:10
 3:27
3:27
2025-10-28 11:18
 3:49
3:49
2025-10-25 12:52
 3:30
3:30
2025-11-02 09:52
 3:00
3:00
2025-11-03 12:33
 3:18
3:18
2025-11-02 10:30
 4:28
4:28
2025-11-03 15:38
0/0
 1:34:38
1:34:38
2025-08-28 15:32
 1:53:35
1:53:35
2025-09-11 08:20
 2:57:46
2:57:46
2025-08-31 01:03
 1:31:23
1:31:23
2025-08-27 18:01
 2:01:55
2:01:55
2025-08-28 15:32
 1:29:32
1:29:32
2025-09-15 11:39
 1:33:34
1:33:34
2025-10-08 12:27
 1:46:40
1:46:40
2025-10-07 09:27
 1:53:29
1:53:29
2025-10-01 12:06
 1:51:56
1:51:56
2025-09-24 11:35
 1:46:45
1:46:45
2025-10-02 20:45
 1:38:22
1:38:22
2025-10-01 12:16
 2:35:53
2:35:53
2025-08-26 11:45
 1:39:41
1:39:41
2025-10-29 16:30
 1:46:00
1:46:00
2025-08-27 17:17
 1:35:11
1:35:11
2025-10-13 12:06
 1:36:20
1:36:20
2025-10-09 20:02
 1:54:48
1:54:48
2025-10-01 15:17
 1:34:43
1:34:43
2025-09-09 12:49
 2:09:55
2:09:55
2025-10-05 00:32
0/0
 12:12
12:12
2024-11-29 14:21
 13:00
13:00
2024-12-02 13:15
 1:50:38
1:50:38
2025-10-29 16:37
 3:28
3:28
2025-01-09 17:01
 1:05:15
1:05:15
2025-09-30 13:45
 12:34
12:34
2024-12-02 14:42
 13:42
13:42
2024-11-28 14:12
 3:27
3:27
2024-12-07 11:00
 7:11
7:11
2025-01-13 11:05
2021-09-22 22:40
2021-09-22 21:17
2021-09-23 00:12
2021-09-22 21:43
 6:30
6:30
2022-03-31 13:09
 7:09
7:09
2023-07-06 19:20
 7:09
7:09
2025-08-19 17:20
 12:08
12:08
2025-06-10 14:59
 25:31
25:31
2022-04-01 14:30
2021-09-22 21:29
 7:35
7:35
2025-11-01 09:00
0/0